Yesterday I had a problem again that at first glance couldn't be solved. A customer has received a warning from a lawyer that he is no longer allowed to use a certain word on his website.

Now you might think: No problem, that's what the search function for pages and posts is for in Wordpress. That's true too, but unfortunately the search function does not include sliders, meta tags or similar, which is managed via plugins in the database. Hard-coded content in the sidebar and in the footer area or in any PHP theme files is not recorded either.
Important note: I'm not offering legal advice or anything like that. Please contact a lawyer for this. My guide is just a technical solution on how to find a specific word in a Wordpress blog that you want to remove or change.
Chapter in this post:
- 1 Google search only partially helpful
- 2 Offline reader SiteSucker loads all sub-pages onto the Mac
- 3 Sensible settings at SiteSucker
- 4 Browse website folders - with BBEdit
- 5 possible pitfalls: image file names and image content
- 6 Conclusion: A lot of work solved with a reasonably manageable effort
- 7 Similar posts
Google search only partially helpful
The Google search with the search query ala “site:www.sir-apfelot.de bad word” is unfortunately no help either, since it only ejects archived data that is a few days old. And there's no way to search Google to ensure you haven't missed a change on the site. You would have to wait until the Google bot has re-indexed all pages and then search again.
Unfortunately, with letters from attorneys, you rarely have enough time to force Google to re-index the page in order to check the pages again using a Google search. So another way of searching the website has to be found.
And the second challenge is: If you make the same mistake again after receiving a warning, it will usually be really expensive. For this reason I have to make double sure that the term is not overlooked somewhere on a subpage.
Offline reader SiteSucker loads all sub-pages onto the Mac
My solution was designed in such a way that I first wanted to load the entire website, including all subpages, onto my Mac and then let BBEdit search through it with the multi-file search.
However, if a website is based on a CMS like Wordpress, you cannot simply download the pages via FTP, as these are dynamically assembled from template files and content from the database.
A free tool called “SiteSucker"(App store link), which runs on the Mac and gives you the opportunity to save a complete website with all sub-pages, graphics and other files. SiteSucker was originally intended to offer a kind of offline reader function. This means that you load the content of a website onto your Mac and the URLs are rewritten by the program so that you can also view the website locally offline on your Mac. It used to be useful when you were on vacation, but nowadays you have WiFi everywhere and no need for such programs.
For my purpose, SiteSucker is the perfect tool, because I want the entire website to be available locally so that I can search through the source code.
[appbox app store 442168834]
Sensible settings at SiteSucker
Since many Wordpress sites are now equipped with security plugins that block automated requests, SiteSucker should be set to always allow 3 to 5 seconds between page loads so that no plugins are triggered. Many hosters also have firewalls running on the server side that recognize when a bot sends multiple requests per second.
If you let SiteSucker go without restrictions on a website, there is a high chance that your own IP will be blocked and you will not be able to access the corresponding website for a few minutes.
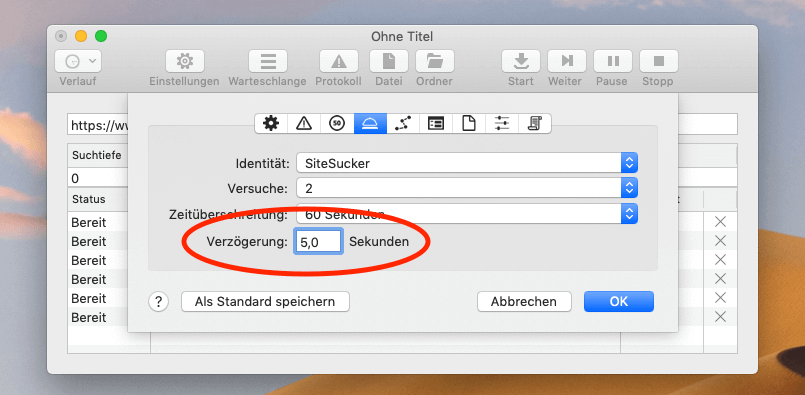
You can also limit the requests by excluding - in my case - files of the type JS, JPEG, GIF, PNG and CSS. This should actually be very easy to do via the settings, but it didn't work for me.
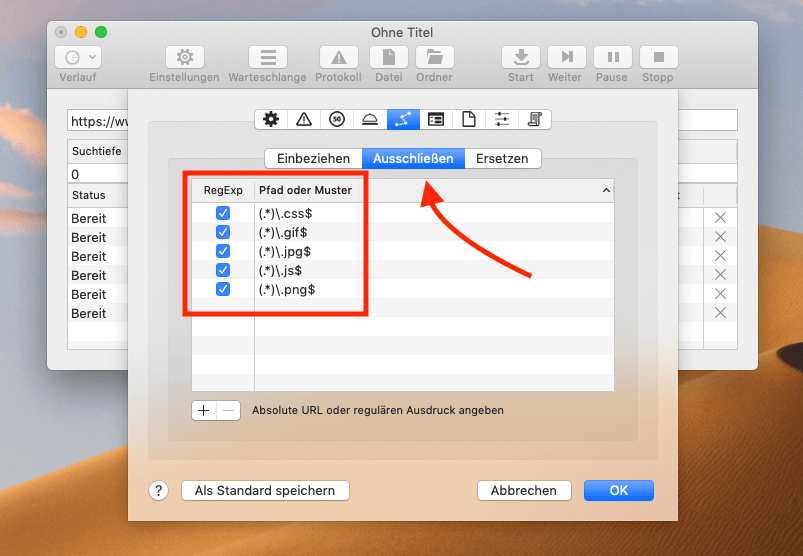
At some point I worked with a few regular expressions that can also be used to exclude files and URLs. If you want to do that too, you can find the appropriate screenshot with the necessary entries here:
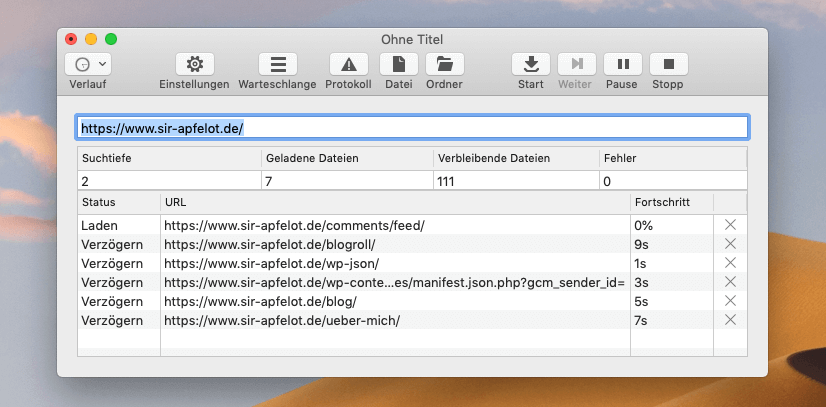
Now click on the start button and watch how SiteSucker works its way through the website and backs up all files one by one. You can also quickly see whether the regex (regular expressions) are working correctly, because all files are displayed live in the list. If you see JPG files there, something on the filter did not work.
Search website folders - with BBEdit
When SiteSucker is through, you have a folder with all the HTML files in which the corresponding "bad word" could be hiding. I searched these with BBEdit's multi-file search function, which opens the files and searches for the word in the source text.
I couldn't try whether Spotlight would work here too, there my spotlight for weeks has a quirk (Clean Install is due in the next few days!). But with BBEdit it worked without any problems and I think, in principle, it can Spotlight also work with HTML content. The only question is whether he would also find words in the source text (image tags, etc.).
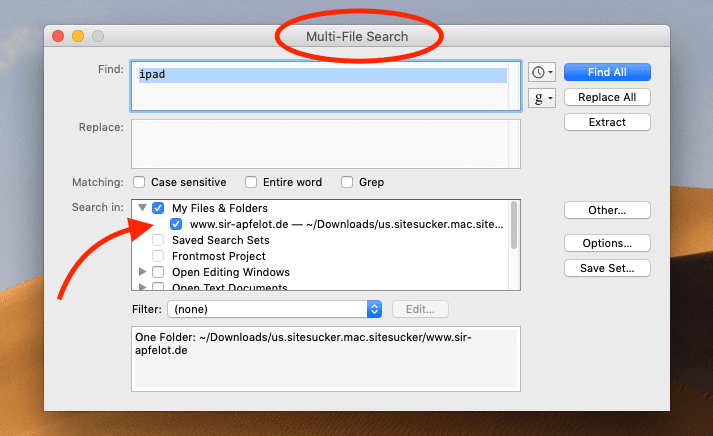
When searching in HTML files you have to keep in mind that you will miss words with umlauts on some websites because the HTML special character may have been used for the corresponding umlaut (see SelfHTML).
An example: instead of “pot roast” can there too “pot roast” to stand.
If you know that, you can change the search accordingly and should then find all occurrences. With this “list of locations” I then went to the Wordpress admin to clean up all the pages.
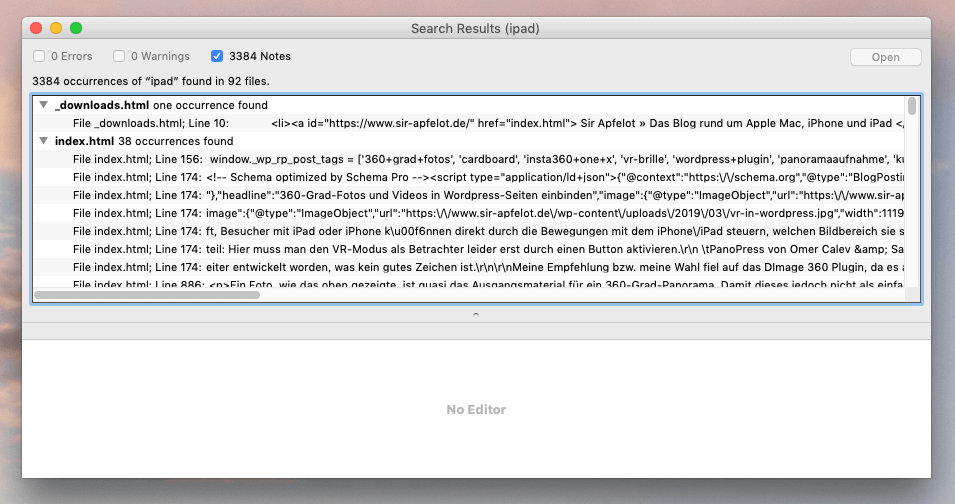
Possible pitfalls: image file names and image content
I only noticed two possible problem areas in the matter later: The word searched for can also be hidden in image file names or even in the image itself. The customer couldn't tell me whether just naming a file with the problematic term would be enough to cause problems again, so we decided to defuse everything.
The search for files with the corresponding name also took place locally in the “Uploads” folder of Wordpress. For this I have (because of a defective spotlight) on the tool Find Any File from Thomas Tempelmann, who had successfully completed the job in a fraction of a second.

The last construction site is the search in image content. That is, photographs, banners or the like, in which the word you are looking for has been incorporated using image processing. These occurrences must also be removed. However, none of the tools I know of help here and you simply have to “scroll” through the graphics by hand with the preview.
I then “cleaned up” problematic graphics and photographs using Photoshop and uploaded them to the server again via FTP. Since I didn't want to rework every thumbnail, I only reworked and swapped out the "big" image versions and then used all the thumbnails with the plugin "Force Regenerate Thumbnails” by Pedro Elsner.
Conclusion: A lot of work solved with a reasonably manageable effort
On the whole, things could be resolved in a reasonable time despite the many sub-pages and graphics. If you have to struggle with such problems and don't know how I can solve a certain task semi-automatically, write a short comment or email me directly. Maybe I can help you!
Related Articles
 AltStore in the test: iPhone sideloading (and game emulation) tried out
AltStore in the test: iPhone sideloading (and game emulation) tried out- 5 app recommendations in April 2024
- Apple iWork 14.0 – Updates for Pages, Numbers and Keynote
- MacPaw releases revised ClearVPN offering
- Epic Games Store announced for iOS and Android
- Adobe alternatives: replacement for Premiere Pro (and partly After Effects)
- Download Apple iLife: Sources for old software and more
- [solved] Affinity Photo: Brush does not paint opaquely despite 100% opacity and hardness






![[solved] Affinity Photo: Brush does not paint opaquely despite 100% opacity and hardness](https://a391e752.rocketcdn.me/wp-content/uploads/2024/03/affinity-photo-pinsel-deckend-150x150.jpg)
Jens has been running the blog since 2012. He acts as Sir Apfelot for his readers and helps them with technical problems. In his spare time he rides electric unicycles, takes photos (preferably with the iPhone, of course), climbs around in the Hessian mountains or hikes with the family. His articles deal with Apple products, news from the world of drones or solutions to current bugs.
Why not just search the MySQL database for the term with phpMyAdmin? At least with self-hosted Worspress sites that shouldn't be a problem ... or am I missing something?
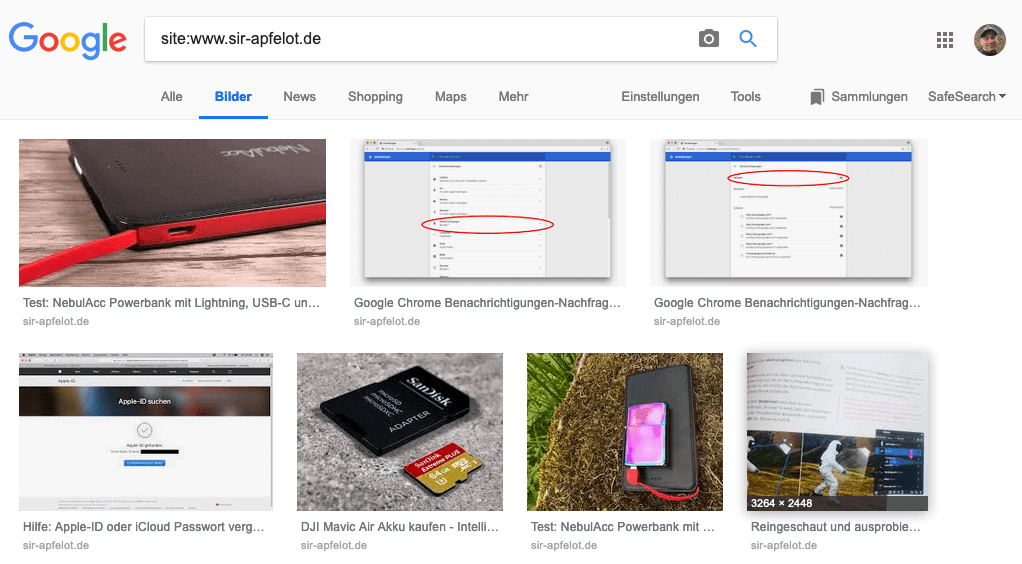
In principle, this is also an approach, but you won't find any image files that have been uploaded but are no longer linked in a post. The Google image search and the opposing lawyer may find it. ;-)
And I have some customers who still have themes where my predecessors programmed menus and small message boxes or changing headers directly into the theme code. They go through the mesh with it.
Thanks for the hint with the picture files.
It would also have been interesting which word was warned (but you are no longer allowed to write that). Possibly there is still a danger in the comments.
I wish the warning lawyer three months of constipation, his clients three months of diarrhea and flatulence.
Hello Kenneth! That was something very special: Someone who attaches insulated sandwich profile sheets as a roof must not speak of "roof covering", since this term is probably reserved for roofers who also "cover roof tiles". Don't ask me for details. :D
And yes, theoretically there is also a danger in comments, but on the one hand my way of searching also finds mention in comments and on the other hand I always switch off the comment function on company websites. So in that respect there was no danger in the current case. And because of your wishes: Yes, I wish him that with you! : D
I think the reference to the database actually makes sense when it comes to WordPress. Theoretically, it is certainly possible that text strings are "drawn" from this before/at the time of delivery of the page(s), which then only appear in the source code of the pages as displayed by the visitor's browser, right? (These are not in any PHP files of the WordPress installation on the server.)
I recently had the case that – past WordFence – some hacks had been used to inject malware-suspicious URLs into the "Description" fields of the site graphics. And this information should at least initially ONLY be in the database (ie not written in the image file) and from there on the server it should be reinserted into the page source text arriving at the site visitor. Or am I wrong?
Hi Peter! Yes, of course you can also search the database, but you will also find hits in revisions and in other places. In my opinion, the "Description" field in the media library is just text that helps you with administration. It is not displayed on an image in the frontend. For this reason, malware URLs should not work there either. But if a hacker can post such URLs anywhere, caution is always advised. After all, he has somehow already gained access to your database, or at least part of it. In such cases, I always check to see if a new user doesn't appear in the "Users" area by chance. Has happened to me several times.
Indeed: Caution is advised ... However: there were actually no new users who were not set up by myself and the existing ones (except me) all only have the subscriber role, in which they are not allowed to have access to such things. There is also no comment function active on the site. The HOW of this code infiltration is therefore a great mystery to me. Maybe via the contact form?
Somehow the URL in question must have somehow made it into the frontend, even if not immediately visible. At least Chrome was able to detect the presence on all pages that contained one of the affected graphics and (if not for all visitors to the page) issue a corresponding warning. On the other hand, I think that Firefox strangely did not produce any matches when searching for the URL in the source text (as it arrived at it) - very strange indeed!
The “Description” field for the images in the media library was only marginally noted and I had never used it (ie always left blank). However, if I understood it correctly during my research, you should be able to read the content in the frontend if the image has a link to itself and you can then call it up with a click. Then the “description” text should be an attachment that is displayed with the image (or something like that…).
The malware usually comes in via some kind of plugin. Funny way even now and then about security holes in Wordfence, although the plugin is supposed to protect against that. But I've read about it several times and on two or three pages I was lucky enough to be able to trace the hacker back to the plugin by the date of the file changes. I haven't used Wordfence since then. : D
Because of the descriptive text: Yes, maybe it uses some function. But when the image is large, most themes will display the caption for the image. But you never stop learning. Maybe I am wrong!
Interesting article, thank you very much. Was the work really successful and did the opposing lawyer keep his feet still afterwards or did something follow suit?
How high was the effort involved until everything was really cleaned up?
Hello Alex! Yes, it was actually successful. Nothing came back from the lawyer, but I'm sure they looked. The second offense is always much more worthwhile for the other side. I can no longer estimate the effort. But I think it was easily half a day or more.