Gestern hatte ich mal wieder ein Problem, zu dem es auf den ersten Blick keine Lösung gab. Ein Kunde hat von einem Anwalt in Form einer Abmahnung mitgeteilt bekommen, dass er ein bestimmtes Wort nicht mehr auf seiner Webseite nutzen darf.

Nun könnte man meinen: Kein Problem, dafür gibt es doch in WordPress die Suchfunktion bei Seiten und Beiträgen. Das stimmt auch, aber die Suchfunktion schließt leider keine Slider, Meta-Tags oder ähnliches ein, was über Plugins in der Datenbank verwaltet wird. Auch fest einprogrammierte Inhalte in Sidebar und im Footerbereich oder in irgendwelchen PHP-Theme-Dateien werden nicht erfasst.
Wichtiger Hinweis: Ich biete hiermit keine Rechtsberatung oder ähnliches. Dafür wendet euch bitte an einen Anwalt. Meine Anleitung ist nur eine technische Lösung, wie man in einem WordPress Blog ein bestimmtest Wort ausfindig macht, das man entfernen oder ändern möchte.
Kapitel in diesem Beitrag:
- 1 Google-Suche nur bedingt hilfreich
- 2 Offline-Reader SiteSucker lädt alle Unterseiten auf den Mac
- 3 Sinnvolle Einstellungen bei SiteSucker
- 4 Webseiten-Ordner durchsuchen – mit BBEdit
- 5 Mögliche Stolperfallen: Bild-Dateinamen und Bildinhalte
- 6 Fazit: Viel Arbeit mit halbwegs überschaubarem Aufwand gelöst
Google-Suche nur bedingt hilfreich
Die Google-Suche mit der Suchanfrage ala "site:www.sir-apfelot.de böses Wort" ist leider auch keine Hilfe, da diese nur archivierte Daten auswirft, die einige Tage alt sind. Und es gibt keine Art der Suche auf Google, die sicherstellt, dass man bei den Änderungen auf der Webseite nichts übersehen hat. Dafür müsste man warten, bis der Google-Bot alle Seiten neu indexiert hat und dann wieder suchen.
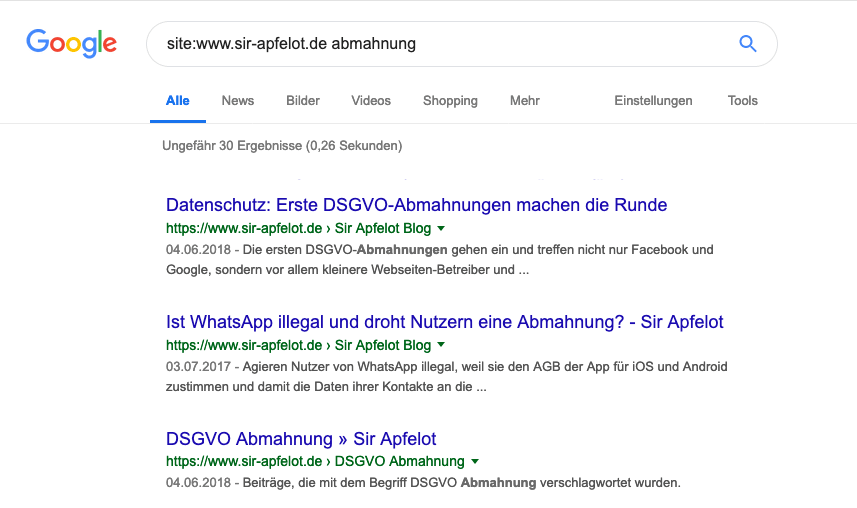
Bei Anwaltschreiben hat man aber leider selten soviel Zeit, dass man Google nötigen könnte, die Seite neu zu indexieren, um die Seiten nochmal per Google-Suche zu prüfen. Also muss ein anderer Weg her, um die Webseite genau zu durchsuchen.
Und die zweite Herausforderung ist: Wenn man nach einer Abmahnung den gleichen Fehler nochmal macht, wird es in der Regel richtig teuer. Aus dem Grund muss ich doppelt sicher gehen, dass nicht irgendwo auf einer Unterseite der Begriff übersehen wird.
Offline-Reader SiteSucker lädt alle Unterseiten auf den Mac
Meine Lösung war so gestaltet, dass ich erstmal die komplette Webseite inklusive aller Unterseiten auf meinen Mac laden und diese dann mit der Multi-File-Suche von BBEdit durchsuchen lassen wollte.
Wenn eine Webseite allerdings auf einem CMS wie WordPress basiert, kann man nicht einfach die Seiten per FTP runterladen, da diese aus Template-Dateien und Inhalten aus der Datenbank dynamisch zusammen gebaut werden.
Hilfe bietet hier ein kostenloses Tool namens "SiteSucker" (App Store Link), das am Mac läuft und einem die Möglichkeit gibt, eine komplette Internetseite mit allen Unterseiten, Grafiken und anderen Dateien zu sichern. Ursprünglich gedacht war SiteSucker wohl, um eine Art Offline-Reader-Funktion zu bieten. Das heißt, man lädt sich die Inhalte einer Webseite auf den Mac und die URLs werden vom Programm so umgeschrieben, dass man die Webseite auch offline lokal an seinem Mac anschauen kann. Früher war das vielleicht sinnvoll, wenn man im Urlaub war, aber heutzutage hat man ja überall WLAN und keinen Bedarf für solche Programme.
Für meinen Zweck ist SiteSucker aber das perfekte Tool, da ich ja die komplette Webseite lokal vorliegen haben möchte, um sie im Quelltext zu durchsuchen.
[appbox appstore 442168834]
Sinnvolle Einstellungen bei SiteSucker
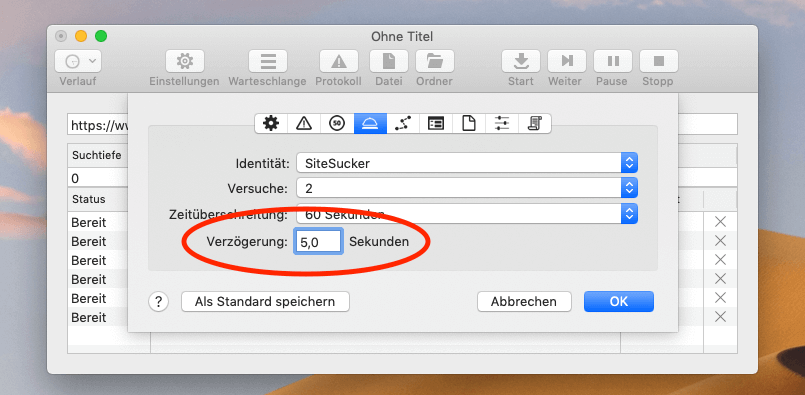
Da viele WordPress-Seiten inzwischen mit Sicherheits-Plugins ausgestattet sind, die automatisierte Anfragen blocken, sollte man in SiteSucker einstellen, dass er zwischen den Ladevorgängen der Seiten immer 3 bis 5 Sekunden Zeit läßt, damit kein Plugin anschlägt. Auch viele Hoster haben serverseitig Firewalls laufen, die erkennen, wenn ein Bot mehrere Anfragen pro Sekunde verschickt.
Wenn man SiteSucker also ohne Einschränkungen auf eine Webseite losläßt, besteht eine hohe Chance, dass die eigene IP gesperrt wird und man erstmal für einige Minuten nicht mehr auf die entsprechende Webseite zugreifen kann.
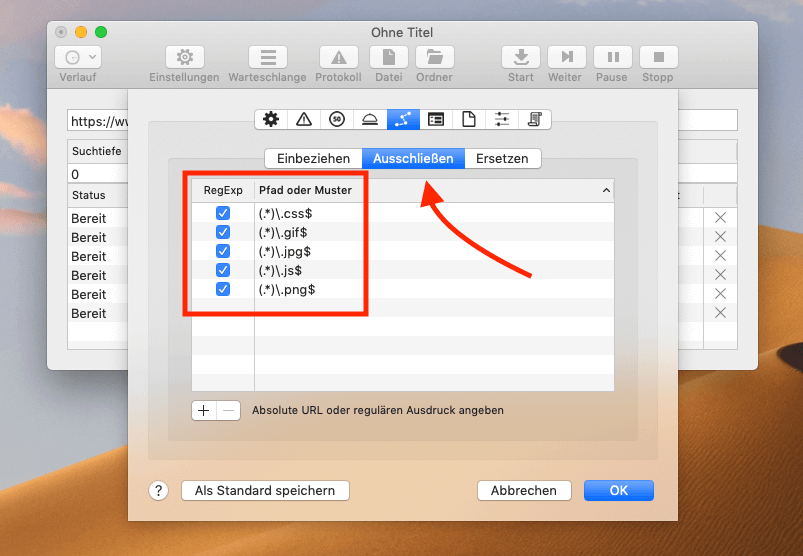
Ebenso kann man die Anfragen begrenzen, indem man – in meinem Fall – Dateien vom Typ JS, JPEG, GIF, PNG und CSS ausschließt. Dies sollte eigentlich über die Einstellungen ganz leicht möglich sein, aber es hat bei mir nicht geklappt.
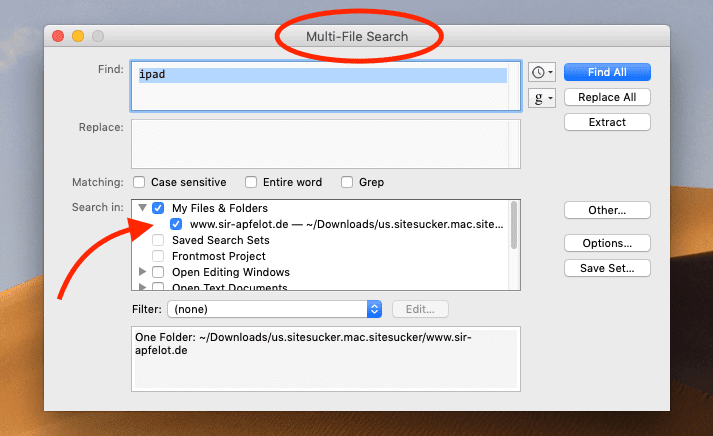
Ich habe dann irgendwann mit einigen regulären Ausdrücken gearbeitet, über die sich auch Dateien und URLs ausschließen lassen. Wenn ihr das ebenfalls machen möchtet, findet ihr hier den passenden Screenshot mit den nötigen Einträgen:
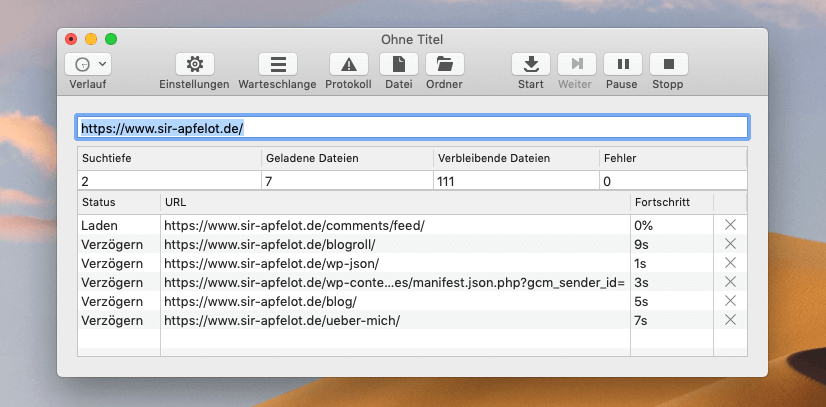
Nun klickt man auf den Start-Button und kann zuschauen, wie sich SiteSucker durch die Webseite arbeitet und alle Dateien nach und nach sichert. Man sieht auch schnell, ob die Regex (regulären Ausdrücke) richtig funktionieren, denn alle Dateien werden in der Liste live angezeigt. Sieht man dort JPG-Dateien, hat irgendwas am Filter nicht geklappt.
Webseiten-Ordner durchsuchen – mit BBEdit
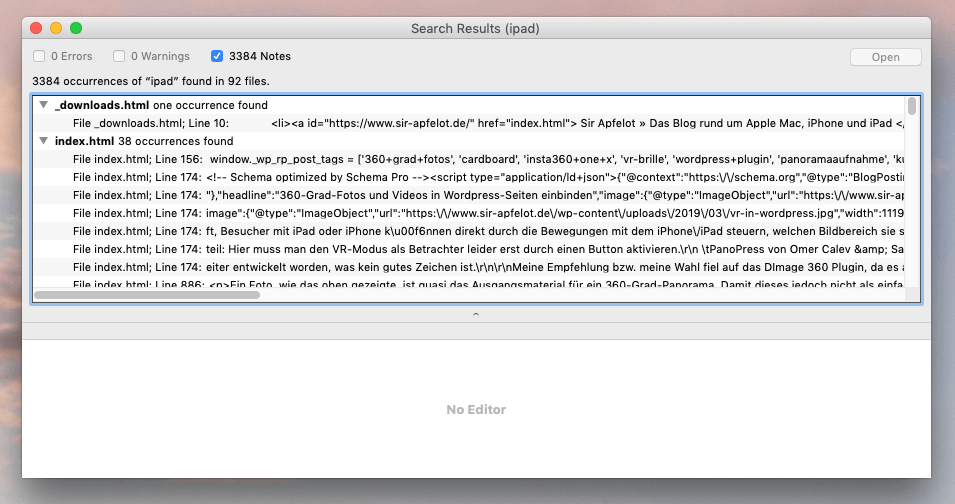
Ist SiteSucker durch, hat man einen Ordner mit den ganzen HTML-Dateien, in denen sich das entsprechende "böse Wort" verstecken könnte. Diese habe ich mit der Multi-File-Suchfunktion von BBEdit durchsucht, denn dieser öffnet die Dateien und sucht im Quelltext nach dem Wort.
Ob hier auch Spotlight funktionieren würde, konnte ich nicht ausprobieren, da mein Spotlight seit Wochen eine Macke hat (Clean Install steht in den nächsten Tagen an!). Mit BBEdit hat es aber problemlos funktioniert und ich denke, prinzipiell kann Spotlight auch mit HTML-Inhalten arbeiten. Fraglich ist nur, ob er auch Worte im Quelltext (Image-Tags etc.) finden würde.
Bei der Suche in HTML-Dateien muss man noch bedenken, dass man bei manchen Webseiten Worte mit Umlauten übersehen wird, weil eventuell das HTML-Sonderzeichen für den entsprechenden Umlaut genutzt wurde (siehe SelfHTML).
Ein Beispiel: statt "Schmörebröt" kann dort auch "Schmörebröt" stehen.
Wenn man das weiss, kann man die Suche entsprechend ändern und sollte dann alle Vorkommnisse finden. Mit dieser "Liste der Fundstellen" habe ich mich dann im WordPress-Admin dran gemacht, um alle Seiten zu bereinigen.
Mögliche Stolperfallen: Bild-Dateinamen und Bildinhalte
Zwei mögliche Problembereiche bei der Sache sind mir erst später aufgefallen: Das gesuchte Wort kann sich auch in Bild-Dateinamen oder sogar im Bild selbst verstecken. Der Kunde konnte mir nicht sagen, ob alleine die Benennung einer Datei mit dem problematischen Begriff schon ausreichen würde, damit er erneut Probleme bekommt, darum haben wir uns dazu entschlossen, alles zu entschärfen.
Die Suche nach Dateien mit dem entsprechenden Namen erfolgte bei mir ebenfalls lokal im "Uploads"-Ordner von WordPress. Dazu habe ich (wegen defektem Spotlight) auf das Tool Find Any File von Thomas Tempelmann zurück gegriffen, das den Job in Sekundenbruchteilen erfolgreich erledigt hatte.

Die letzte Baustelle, ist die Suche in Bildinhalten. Das heißt, Fotografien, Banner oder ähnliches, in denen das gesuchte Wort per Bildbearbeitung eingebaut wurde. Auch diese Vorkommnisse müssen entfernt werden. Hier hilft jedoch kein mir bekanntes Tool und man muss einfach per Hand mit der Vorschau durch die Grafiken "blättern".
Problematische Grafiken und Fotografien habe ich dann per Photoshop "bereinigt" und wieder per FTP auf den Server geladen. Da ich nicht jedes Thumbnail überarbeiten wollte, habe ich nur die "grossen" Bildversionen überarbeitet und ausgetauscht und dann alle Thumbnails mit dem Plugin "Force Regenerate Thumbnails" von Pedro Elsner neu generieren lassen.
Fazit: Viel Arbeit mit halbwegs überschaubarem Aufwand gelöst
Im Großen und Ganzen konnte die Sachen trotz der vielen Unterseiten und Grafiken in passabler Zeit gelöst werden. Falls ihr auch mal mit solchen Problemen zu kämpfen habt und nicht wisst, wie ich eine bestimmte Aufgabe halbautomatisch lösen könnt, schreibt einen kurzem Kommentar oder mailt mir direkt. Vielleicht kann ich euch helfen!
Ähnliche Beiträge
![PeakLog – Digitales Logbuch für Naturausflüge komplett überarbeitet!]() PeakLog – Digitales Logbuch für Naturausflüge komplett überarbeitet!
PeakLog – Digitales Logbuch für Naturausflüge komplett überarbeitet!![Statt Sidecar: OpenDisplay erweitert Mac-Display auf iPhone und iPad]() Statt Sidecar: OpenDisplay erweitert Mac-Display auf iPhone und iPad
Statt Sidecar: OpenDisplay erweitert Mac-Display auf iPhone und iPad![Kein Plugin: Dieser Browser spielt YouTube-Videos standardmäßig ohne Werbung]() Kein Plugin: Dieser Browser spielt YouTube-Videos standardmäßig ohne Werbung
Kein Plugin: Dieser Browser spielt YouTube-Videos standardmäßig ohne Werbung![Itsyhome: Neue Version mit virtuellen Sensoren und Zeitraum-Auslösern]() Itsyhome: Neue Version mit virtuellen Sensoren und Zeitraum-Auslösern
Itsyhome: Neue Version mit virtuellen Sensoren und Zeitraum-Auslösern![NoGlasshole App: Smart Glasses Scanner mit ein paar Kritikpunkten]() NoGlasshole App: Smart Glasses Scanner mit ein paar Kritikpunkten
NoGlasshole App: Smart Glasses Scanner mit ein paar Kritikpunkten![Neu bei WhatsApp: Was bedeutet der grüne Punkt? Wie deaktiviert man ihn?]() Neu bei WhatsApp: Was bedeutet der grüne Punkt? Wie deaktiviert man ihn?
Neu bei WhatsApp: Was bedeutet der grüne Punkt? Wie deaktiviert man ihn?![5 neue Apps für macOS 27, iPadOS 27, iOS 27 und watchOS 27]() 5 neue Apps für macOS 27, iPadOS 27, iOS 27 und watchOS 27
5 neue Apps für macOS 27, iPadOS 27, iOS 27 und watchOS 27![Siri AI: Pausen-Empfehlung und Erinnerung, dass es keine echte Person ist]() Siri AI: Pausen-Empfehlung und Erinnerung, dass es keine echte Person ist
Siri AI: Pausen-Empfehlung und Erinnerung, dass es keine echte Person ist








Seit 2012 betreibe ich meinen Blog als Sir Apfelot und helfe meinen Lesern bei technischen Problemen. In meiner Freizeit flitze ich auf elektrischen Einrädern, fotografiere mit meinem iPhone, klettere in den hessischen Bergen oder wandere mit meiner Familie. Meine Artikel behandeln Apple-Produkte, Drohnen-News und Lösungen für aktuelle Bugs.
Warum nicht einfach die MySQL-Datenbank mit phpMyAdmin nach dem Begriff durchsuchen? Zumindest bei selbstgehosteten Worspress-Sites sollte das ja kein Problem sein… oder übersehe ich da etwas?
Prinzipell auch ein Ansatz, aber da findest du keine Bilddateien, die hochgeladen wurden, aber nicht mehr in einem Beitrag verknüpft sind. Die Google-Bildersuche und der gegnerische Anwalt findet die aber unter Umständen schon. ;-)
Und ich habe einige Kunden, die haben noch Themes, wo mein Vorgänger Menüs und kleine Hinweiskästchen oder wechselnde Header direkt im Themecode einprogrammiert haben. Die gehen einem damit auch durch die Maschen.
Danke für den Hinweis mit den Bilddateien.
Interessant wäre auch gewesen, welches Wort abgemahnt wurde (aber das darfst du ja nicht mehr schreiben). Evtl. besteht die Gefahr ja auch noch in den Kommentaren.
Dem abmahnenden Anwalt wünsche ich drei Monate Verstopfung, dessen Mandanten drei Monate Durchfall und Flatulenz.
Hallo Kenneth! Das war was sehr spezielles: Jemand, der isolierte Sandwich-Profilbleche als Dach anbringt, darf nicht von „Dacheindeckung“ sprechen, da dieser Begriff wohl nur Dachdeckern vorbehalten ist, die auch „Dachziegel eindecken“. Frag mich nicht nach Details. :D
Und ja, theoretisch besteht die Gefahr auch in Kommentaren, aber zum einen findet meine Art zu suchen auch die Nennung in Kommentaren und zum anderen schalte ich die Kommentarfunktion bei Firmenwebseiten immer aus. Also in der Hinsicht war im aktuellen Fall keine Gefahr. Und wegen deiner Wünsche: Ja, das wünsche ich ihm mit dir! :D
Ich finde den Hinweis auf die Datenbank eigentlich auch sinnvoll, wenn es um WordPress geht. Theoretisch ist es doch sicher möglich, dass daraus vor/zur Auslieferung der Seite(n) Textstrings „gezogen“ werden, die dann erst im Quelltext der Seiten, wie sie vom Browser des Besuchers dargestellt werden, auftauchen, oder? (Die also nicht in irgendwelchen PHP-dateien der WordPress-Installation auf dem Server liegen.)
Ich hatte kürzlich den Fall, dass – an WordFence vorbei – durch irgendwelche Hacks Malware-verdächtige URLs in die „Beschreibung“-Felder der Site-Grafiken eingeschleust worden waren. Und diese Info dürfte doch zumindest erst einmal NUR in der Datenbank stehen (d.h. nicht in die Bilddatei geschrieben werden) und von dort her auf dem Server wieder in den beim Besucher der Seiten ankommenden Seitenquelltext eingefügt werden. Oder sehe ich das falsch?
Hallo Peter! Ja, man kann natürlich auch die Datenbank durchsuchen, aber da findet man eben auch Treffer in Revisionen und an anderen Stellen. Das Feld „Beschreibung“ ist in der Mediathek meiner Ansicht nach nur ein Text, der dir bei der Verwaltung hilft. Er wird im Frontend nicht bei einem Bild angezeigt. Aus dem Grund dürfte Malware-URLs dort auch nicht funktionieren. Aber wenn ein Hacker solche URLs irgendwo rein posten kann, ist immer Vorsicht geboten. Immerhin hat er sich irgendwie schon den Zugriff auf deine Datenbank oder jedenfalls einen Teil davon verschafft. Ich schaue in solchen Fällen immer mal nach, ob nicht zufällig ein neuer User in dem Bereich „Benutzer“ auftaucht. Ist mir schon mehrmals passiert.
In der Tat: Vorsicht ist geboten… Allerdings: neue, nicht von mir selbst eingerichtete User gab es tatsächlich keine und die bestehenden haben (außer mir) alle nur die Abonnenten-Rolle, in der sie keinen Zugriff auf solche Dinge haben dürften. Auch ist auf der Site keine Kommentarfunktion aktiv. Das WIE dieses Code-Einschleusens ist mir daher ein großes Rätsel. Vielleicht über das Kontaktformular?
Irgendwie muss es die fragliche URL aber doch irgendwie ins Frontend geschafft haben, wenn auch nicht unmittelbar sichtbar. Zumindest konnte Chrome das Vorhandensein auf allen Seiten, die eine der betroffenen Grafiken enthielten, offenbar feststellen und (wenn auch nicht bei allen Besuchern der Seite) eine entsprechende Warnung ausgeben. Andererseits meine ich aber, dass Firefox bei der Suche nach der URL im Quelltext (so wie er bei ihm ankam) merkwürdigerweise keine Matches produzierte – schon sehr merkwürdig!
Das Feld „Beschreibung“ bei den Bildern in der Mediathek hatte ich zuvor auch nur am Rand zur Kenntnis genommen und nie benutzt (d.h. stets leer gelassen). Allerdings soll man den Inhalt – wenn ich es bei meiner Recherche richtig verstanden habe – im Frontend lesen können, wenn das Bild mit einem Link auf sich selbst versehen ist und man es per Klick dann aufrufen kann. Dann soll wohl der „Beschreibung“-Text ein Anhang dazu sein, der mit dem Bild angezeigt wird (oder so ähnlich…).
Die Malware kommt in der Regel über irgendein Plugin rein. Lustiger Weise sogar hin und wieder über Sicherheitslücken in Wordfence, obwohl das Plugin ja genau dagegen schützen soll. Aber darüber habe ich schon mehrfach gelesen und bei zwei, drei Seiten hatte ich auch das Glück, den Hacker durch das Datum der Dateiveränderungen auf das Plugin zurückverfolgen zu können. Seit dem nutze ich Wordfence nicht mehr. :D
Wegen dem Beschreibungstext: Ja, vielleicht nutzt es irgendeine Funktion. Aber wenn das Bild in groß dargestellt wird, zeigen die meisten Themes die Bildunterschrift zum Bild an. Aber man lernt ja nie aus. Vielleicht liege ich falsch!
Interessanter Artikel, vielen Dank. War die Arbeit wirklich erfolgreich und hat der gegnerische Anwalt danach die Füße stillgehalten oder kam da nochmal was nach?
Wie hoch war denn der damit verbundene Aufwand, bis wirklich alles bereinigt war?
Hallo Alex! Ja, das war tatsächlich erfolgreich. Vom Anwalt kam nicht wieder was, aber ich bin sicher, sie haben gesucht. Der zweite Verstoß ist ja immer deutlich lohnenswerter für die Gegenseite. Den Aufwand kann ich jetzt nicht mehr abschätzen. Ich glaube aber, es war locker ein halber Tag oder mehr.